ToxCast assay 데이터 기반 머신러닝 모델 성능 비교: 독성 이진분류 문제에서 클래스 균형도 영향 분석
Comparison of the performance of machine learning models based on ToxCast assay data: the impact of class imbalance in binary classification
Introduction
Ø“Epigenetic” encompasses the full spectrum of transcriptional regulatory processes that is thought to mediate environmental effects, such as chemical exposure, and change cellular and phenotypic state. Epigenetic modification thus can play in combination with other mechanisms by environmental chemicals and has been suggested as the toxic mechanism of various chemicals.
구조-활성 관계(SAR)는 화학물질의 분자 구조로부터 생물학적 활성을 예측하는데 자주 사용된다. SAR기반 화학물질 활성 분류에서에서 해결해야할 가장 큰 문제는 학습데이터의 활성 물질과 비활성 물질 간의 극심한 클래스 불균형 문제이다. SAR기반
기계학습을 이용한 독성예측에서 해결해야할 가장 큰 문제는 학습데이터의 클래스 뷸균형 문제이다. 본 연구에서는 Toxcast데이터를 활용하여
Aim of study
Materials & Methods
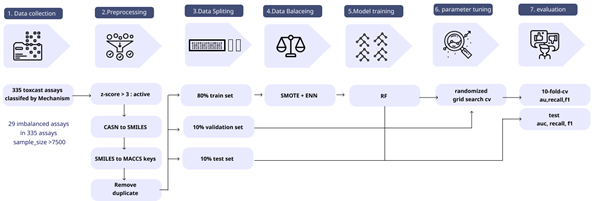
1.Data Collection
2. Preprecessing
3. Data spliting
4. Data balancing
5. Model training
6. parameter tuning
7. evaluation
Result
Table 1. Assay matrix by number of chemicals and data balance (inactive %)
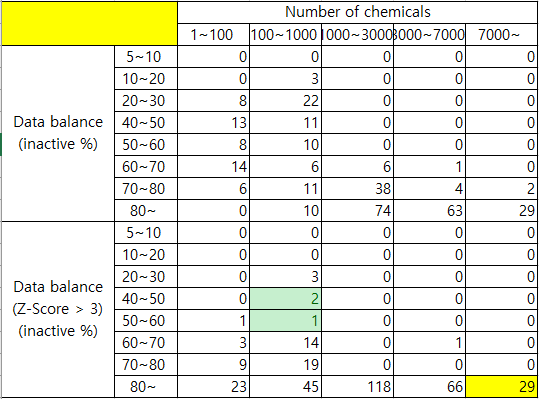
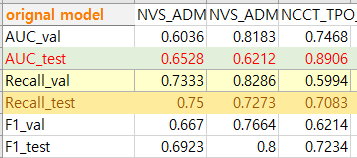
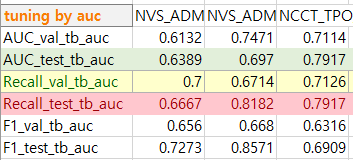
대부분 active비율이 5% 이하로 극심한 불균형을 보입니다
데이터 수가 적었던 3개 assay보다 더 평균적으로 더 좋은 성능을 내는 것을 볼 수 있었습니다


모든 결과를 분석한 결과 불균형 assay로 학습했을 때보다 균형 assay로 학습했을 때 recall과 f1값이 높은 경향을 보였다. 또한 불균형 데이터 세트에서도 파라미터 튜닝 시 recall과 f1값이 상당히 증가했음을 확인했다.
Discussion