GCN(Graph convolutional networks)은 2D molecular graph analysis에 적용된다고 한다.
유사한 개념의 로컬 공간 필터를 사용하지만 주변feature를 학습하기 위해 그래프에서 작동하며
small molecule representations를 학습하기 위한 다양한 GCN 아키텍쳐 제안되었다. -> 각각 다른방식으로 local graph neighborhood와 convolution operations을 수행하는 것.
GCN에 개념에 대하여 정확한 이해가 필요하다.
CNN과는 무엇이 다른가?
www.youtube.com/watch?v=YL1jGgcY78U
분자그래프로부터 logp를 예측하는 프로젝트 해보자.
그래프란 무엇인가?
컨볼루션 연산이란? : 필터를 쭉 이동시키면서 dot product를 하여 새로운 값을 얻어내는 연산.
GCN(Graph convolutional networks)는 그래프 데이터에 컨볼루션 연산을 수행하는 방식으로 피쳐를 뽑아내어 학습한다. 컨볼루션 연산이란 필터를 쭉 이동시키면서 dot product를 하여 새로운 값을 얻어내는 연산이다. GCN은 2D molecular graph analysis에 적용된다. small molecule representations을 학습하기 위해 다양한 GCN 아키텍쳐가 제안되었는데 각각 다른 방식으로 local graph neighborhood을 찾고 convolution operations을 수행하는 것이다.

이미지 표현 : pixel로 표현 흑백의 경우에는 채널 1개에 0~255사이 값 컬러의 경우에는 채널 3개에 0~255사이의 값이 들어가 있음. --> CNN이 적절함 2D filter를 이미지 위에서 이동 시키면서 정보를 추출함.
sentence나 sequentail data는 하나의 charcter or 단어가 배열이 되어있는 형태. --> RNN이 적절함.
이미지나 문장이 아닌 다른 데이터도 있다!

그래프라는 것은 vertics의 set과 edge의 set으로 이루어진 것.
directed, undirected graph 방향성이 있고 없고, weighted graph

각 vertex는 user : 정보를 가지고 있다. edge : relationship(친밀도,좋아요몇번) 등
molecular graph : vertex(node) : 원자(원자의 기호는 뭔지, chemcial balncing등), edge : atom들 간의 결합(1차,2차결합, 이온결합 등등)

어떻게 discreate한 형태로 표현하는가? (전산에 주기 위해서)
graph convolution Network
graph에서 feature를 뽑아내는것. convolution연산을 어떻게 하는것?

filter의 depth는 input tensor에 의해서 자동으로 결정이 된다. filter size or kernal size라고 함.
zero padding을 주고(크기 유지를 위해서), 필터를 stride(몇칸씩 건너 뛸것인가)만큼 이동하면서
75개의 값끼리 dot product해서 하나의 값을 뽑아내어 tensor를 만든다.
필터 하나마다. 28*28 이 나온다.
여기서 중요하게 봐야할 것은 뉴런이 볼 수 있는 범위 (receptive field), 각 layer마다 깊어지면 깊어질수록 recpetive field가 쌓이게 된다. 결과적으로 effective receptive field가 점점 넓어진다. 얕은쪽에선 좁고 깊은 쪽에선 넓어진다.

CNN은 weight sharing이 가능하게 한다. 하나의 필터(shared weight)가 이미지 전체를 sliding하면서 tensor를 추출해 낸다.(RNN도 마찬가지로 weight sharing을 한다. ) weight sharig은 모델 parmaeter수를 감소시켜 overfiiting 위험을 감소시키며 computational cost를 감소시킨다.
CNN에선(이미지에선) local features를 배우게 된다. receptive field라고 부르는 local한 영역에서 정보를 빼내게 된다. RNN에서는 단어마다의 local한 정보를 빼내게 된다.
Translation invariance : mlp에서는 이미지의 픽셀 하나만 달라진다고 해도 값이 확연하게 달라짐, 이미지는 픽셀이 하나 달라진다고 해서 결과값이 달라지지 않는다.

GCN도 CNN의 장점을 그대로 가져가야함. 이미지가 아닌 그래프에 적용시킨다면 구조를 어떻게 바꿔야 할까?
H20 분자그래프의 정보를 결정하는 것 무엇인가? 이미지에서는 activation value에 있는 값들이였다.
그래프의 정보를 결정하는것? --> 각 노드에 담긴 feature
어떤 그래프에 대해서 연산할때.. 그래프 형태는 바뀌지 않고. 노드 정보만. O와 H안에 있는 정보만 바뀌게 되면. 그 정보들이 어떤 분자인지 결정한다 .
graph convolution을 거치게 되면 node feature에 있는 값이 update가 되어야 한다.

어떤 방식으로 update해야 타당한가? --> convolution은 weigh를 sliding하는것.
convolution의 주요한 특성은 1. weight sharing, 2. local feature를 학습(뉴런이 receptive field를 갖게됨),
GCN에서 hidden layer는 무엇을 의미하는가? - mlp에서는 하나의 layer에 있는 값들. - cnn에 경우에는 activation tensor를 hidden layer라고 함. - GCN에서는 각 layer를 거치고 나서의 node featrue matrix를 hidden state라고 부름.
해당 노드에 연결되어있는 노드들의 node feature에 weight를 곱하여 더한다.
%오타 : H1(2+1) 가 아니라 H1(l+1)임
H1이 의미하는것은 hidden state(node featrue matrix)의 1번째 row
H1(자기 자신)에 weight를 곱하고 H2에 weight를 곱하고 ... 인접한 노드들의 node feature에 weight를 곱해서 모두 더한후 마지막에 bias를 더한다. weight가 다 똑같기 때문에 weight sharing을 한다, local 한 feature를 뽑아낸다.

실제로 구현할때에는? 1번 노드에 인접해 있는 애들이 뭔지 보고 wieght곱해서 더한 다음에, 2번 노드에 인접해 있는 애들이 뭔지 보고.. 이렇게 하면 for문을 사용하게 되어 속도가 엄청 느려지게 된다. adjaceny matrix가 connectivity를 나타내는 값이다. 이를 잘 활용하면 gpu가 빠르게 잘 하는 행렬 연산으로 바꿀 수 있다.
그리면서 이해해보도록 하자.

H는 첫번째 layer에서는 (node개수,node당 feature개수)를 가지는 행렬이다. W는(node당 feature개수, filter개수)를 가지는 행렬이다. HW에 A가 곱해지면, 그 행렬의 i번재 행은 i번째 node와 연결된 노드의 피쳐(이전 layer의 피쳐에 filter들을 거친 피쳐)들을 합한 값이다.

permutation이 어떻게 되어있든간에 관계없이.
MLP를 씌우고 activation을 적용하면 permutation invariance하다는 것이 수학적으로 증명되었다.

Advanced Techniques of GCN
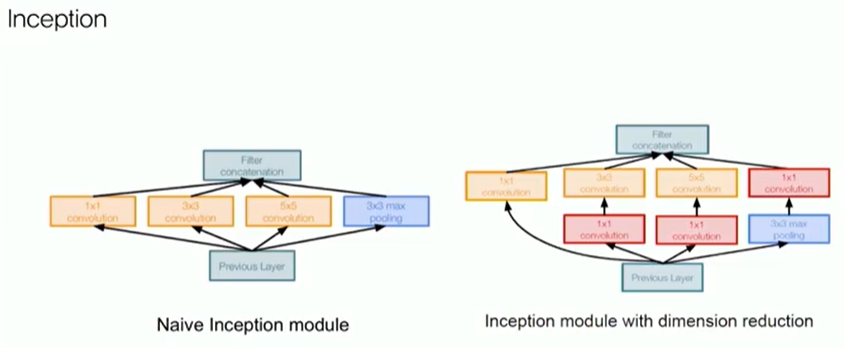
그래프에선 어떻게 할 수 있을까? --> 필터 사이즈가 각각 다르다는 것(receptive field의 크기)
그래프에서는 몇개 거리까지 떨어져 있느냐!( 얼마나 멀리 있는 노드의 정보까지 보느냐)
어떻게 하면 사이즈를 조절할 수 있을까? adjaceny matrix를 한번 더 곱해주면. 거리가 2인 애들까지 된다.

ajdacency matrix를 한번 더 곱해주시면 길이가 2인 애들까지 되는구나. 알 수 있다.

위와 같이 하면 inception module처럼 다양한 receptive field를 가지고 할 수 있다.

resnet에 있던 skip connection.
graph convolution이라고 해서 다르진 않음.

다만 주의할 점은 filter개수, size가 달라져서 feature개수가 달라지게 되면..matrix의 크기가 똑같아야하니까. 크기를 맞춰주어서더해야한다. resnet에서도 똑같이 depth가 달라지거나 max_pooling으로 크기가 달라지면 맞춰주는 과정을 거쳤으니까... simple하게 resnet과 마찬가지로 구현할 수 있다.
gate z를 예측하자. H에 weight곱하고 h에 weight곱해서 bias더하고 sigmoid를 씌워서..
김우연 교수님

알파라는 coeffiecient를 이용해서 적절한 비율로 섞자.! 어떤 neighbor가 중요한지!

실습
GCN layer에 왜 linear를 붙여주는가?
weight 와 행렬곱을 해주었다. mlp에서 했던 것과 똑같다. 결국 linear 레이어를 사용함으로써구현가능하다.
linear에는 input dim과 output dim을 넣어주어야한다.
skip connection은 단순히 더해주는 것인데 사이즈 다를때만 사이즈 맞춰주는 것을 하면 된다
사이즈 맞춰주기 위해서 linear를 하나 거치면 됨.
Gated skip connection은? 뭔가 많아보이네요..
coefficient z를 학습해서 z와 1-z의 비율로. 잘 섞어주겠다 라는 얘기.
아무데서 툭 뒤어나온 값이 아니라. x 와 fx중에 뭐가 더 중요한지 보고 얘내 두개로부터 learning 을 해 야한다.