scikit-learn.org/stable/modules/multiclass.html
1.12. Multiclass and multioutput algorithms — scikit-learn 0.24.1 documentation
1.12. Multiclass and multioutput algorithms This section of the user guide covers functionality related to multi-learning problems, including multiclass, multilabel, and multioutput classification and regression. The modules in this section implement meta-
scikit-learn.org
This section of the user guide covers functionality related to multi-learning problems, including multiclass, multilabel, and multioutput classification and regression.
The modules in this section implement meta-estimators, which require a base estimator to be provided in their constructor. Meta-estimators extend the functionality of the base estimator to support multi-learning problems, which is accomplished by transforming the multi-learning problem into a set of simpler problems, then fitting one estimator per problem.
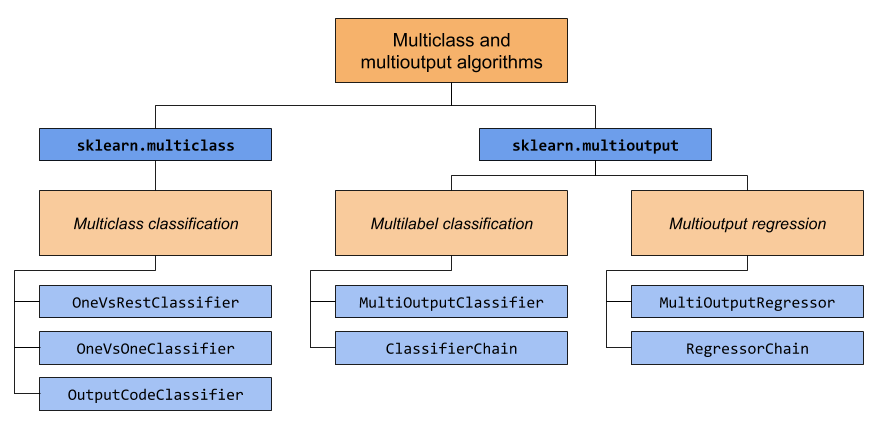
This section covers two modules: sklearn.multiclass and sklearn.multioutput. The chart below demonstrates the problem types that each module is responsible for, and the corresponding meta-estimators that each module provides.
사용자 가이드의이 섹션에서는 다중 클래스, 다중 레이블, 다중 출력 분류 및 회귀를 포함하여 다중 학습 문제와 관련된 기능을 다룹니다.
이 섹션의 모듈은 생성자에 기본 추정기가 제공되어야하는 메타 추정기를 구현합니다. 메타 추정기는 기본 추정기의 기능을 확장하여 다중 학습 문제를 지원합니다. 다중 학습 문제를 더 간단한 문제 집합으로 변환 한 다음 문제당 하나의 추정기를 피팅하여 수행합니다.
이 섹션에서는 sklearn.multiclass 및 sklearn.multioutput의 두 모듈을 다룹니다. 아래 차트는 각 모듈이 담당하는 문제 유형과 각 모듈이 제공하는 해당 메타 추정기를 보여줍니다.
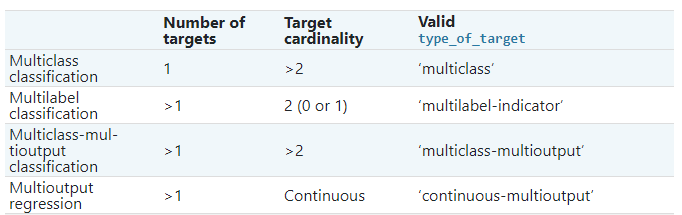
The table below provides a quick reference on the differences between problem types. More detailed explanations can be found in subsequent sections of this guide.
아래 표는 문제 유형 간의 차이점에 대한 빠른 참조를 제공합니다. 더 자세한 설명은이 가이드의 다음 섹션에서 찾을 수 있습니다.
cardinality: 집합의 크기
1.12.1. Multiclass classification
Warning
All classifiers in scikit-learn do multiclass classification out-of-the-box. You don’t need to use the sklearn.multiclass module unless you want to experiment with different multiclass strategies.
경고
scikit-learn의 모든 분류기는 즉시 다중 클래스 분류를 수행합니다. 다른 멀티 클래스 전략을 실험하려는 경우가 아니면 sklearn.multiclass 모듈을 사용할 필요가 없습니다.
Multiclass classification is a classification task with more than two classes. Each sample can only be labeled as one class.
For example, classification using features extracted from a set of images of fruit, where each image may either be of an orange, an apple, or a pear. Each image is one sample and is labeled as one of the 3 possible classes. Multiclass classification makes the assumption that each sample is assigned to one and only one label - one sample cannot, for example, be both a pear and an apple.
While all scikit-learn classifiers are capable of multiclass classification, the meta-estimators offered by sklearn.multiclass permit changing the way they handle more than two classes because this may have an effect on classifier performance (either in terms of generalization error or required computational resources).
다중 클래스 분류는 세 개 이상의 클래스가있는 분류 작업입니다. 각 샘플은 하나의 클래스로만 레이블을 지정할 수 있습니다.
예를 들어, 과일 이미지 세트에서 추출한 특징을 사용하는 분류입니다. 각 이미지는 오렌지, 사과 또는 배일 수 있습니다. 각 이미지는 하나의 샘플이며 세 가지 가능한 클래스 중 하나로 레이블이 지정됩니다. 다중 클래스 분류는 각 샘플이 하나의 레이블에만 할당되어 있다고 가정합니다. 예를 들어 하나의 샘플은 배와 사과가 될 수 없습니다.
모든 scikit-learn 분류기는 다중 클래스 분류가 가능하지만 sklearn.multiclass에서 제공하는 메타 추정기는 분류기 성능에 영향을 미칠 수 있기 때문에 (일반화 오류 또는 필요한 계산에 따라) 둘 이상의 클래스를 처리하는 방식을 변경할 수 있습니다. 자원).
1.12.1.2. OneVsRestClassifier
The one-vs-rest strategy, also known as one-vs-all, is implemented in OneVsRestClassifier. The strategy consists in fitting one classifier per class. For each classifier, the class is fitted against all the other classes. In addition to its computational efficiency (only n_classes classifiers are needed), one advantage of this approach is its interpretability. Since each class is represented by one and only one classifier, it is possible to gain knowledge about the class by inspecting its corresponding classifier. This is the most commonly used strategy and is a fair default choice.
one-vs-all이라고도하는 one-vs-rest 전략은 OneVsRestClassifier에서 구현됩니다. 전략은 클래스 당 하나의 분류자를 맞추는 것으로 구성됩니다. 각 분류기에서 클래스는 다른 모든 클래스에 적합합니다. 계산 효율성 (n_classes 분류 자만 필요) 외에도이 접근 방식의 한 가지 장점은 해석 가능성입니다. 각 클래스는 단 하나의 분류기로 표현되기 때문에 해당 분류기를 검사하여 클래스에 대한 지식을 얻을 수 있습니다. 이것은 가장 일반적으로 사용되는 전략이며 공정한 기본 선택입니다.
1.12.2. Multilabel classification
Multilabel classification (closely related to multioutput classification) is a classification task labeling each sample with m labels from n_classes possible classes, where m can be 0 to n_classes inclusive. This can be thought of as predicting properties of a sample that are not mutually exclusive. Formally, a binary output is assigned to each class, for every sample. Positive classes are indicated with 1 and negative classes with 0 or -1. It is thus comparable to running n_classes binary classification tasks, for example with MultiOutputClassifier. This approach treats each label independently whereas multilabel classifiers may treat the multiple classes simultaneously, accounting for correlated behavior among them.
For example, prediction of the topics relevant to a text document or video. The document or video may be about one of ‘religion’, ‘politics’, ‘finance’ or ‘education’, several of the topic classes or all of the topic classes.
다중 레이블 분류 (다중 출력 분류와 밀접하게 관련됨)는 n_classes 가능한 클래스의 m 레이블로 각 샘플에 레이블을 지정하는 분류 작업입니다. 여기서 m은 0부터 n_classes까지 포함될 수 있습니다. 이것은 상호 배타적이지 않은 샘플의 특성을 예측하는 것으로 생각할 수 있습니다. 공식적으로 이진 출력은 모든 샘플에 대해 각 클래스에 할당됩니다. 포지티브 클래스는 1로 표시되고 네거티브 클래스는 0 또는 -1로 표시됩니다. 따라서 예를 들어 MultiOutputClassifier를 사용하여 n_classes 이진 분류 작업을 실행하는 것과 비슷합니다. 이 접근 방식은 각 레이블을 독립적으로 처리하는 반면 다중 레이블 분류기는 여러 클래스를 동시에 처리하여 상호 관련된 동작을 설명 할 수 있습니다.
예를 들어, 텍스트 문서 또는 비디오와 관련된 주제 예측. 문서 나 동영상은 '종교', '정치', '금융'또는 '교육'중 하나, 여러 주제 수업 또는 모든 주제 수업에 관한 것일 수 있습니다.
1.12.3. Multiclass-multioutput classification¶
Multiclass-multioutput classification (also known as multitask classification) is a classification task which labels each sample with a set of non-binary properties. Both the number of properties and the number of classes per property is greater than 2. A single estimator thus handles several joint classification tasks. This is both a generalization of the multilabel classification task, which only considers binary attributes, as well as a generalization of the multiclass classification task, where only one property is considered.
For example, classification of the properties “type of fruit” and “colour” for a set of images of fruit. The property “type of fruit” has the possible classes: “apple”, “pear” and “orange”. The property “colour” has the possible classes: “green”, “red”, “yellow” and “orange”. Each sample is an image of a fruit, a label is output for both properties and each label is one of the possible classes of the corresponding property.
Note that all classifiers handling multiclass-multioutput (also known as multitask classification) tasks, support the multilabel classification task as a special case. Multitask classification is similar to the multioutput classification task with different model formulations. For more information, see the relevant estimator documentation.
다중 클래스 다중 출력 분류 (멀티 태스크 분류라고도 함)는 비 이진 속성 세트로 각 샘플에 레이블을 지정하는 분류 태스크입니다. 속성의 수와 속성 당 클래스의 수는 모두 2보다 큽니다. 따라서 단일 추정기는 여러 공동 분류 작업을 처리합니다. 이것은 이진 속성 만 고려하는 다중 레이블 분류 작업의 일반화와 하나의 속성 만 고려되는 다중 클래스 분류 작업의 일반화입니다.
예를 들어, 과일 이미지 세트에 대한 속성 "과일 유형"및 "색상"의 분류. "과일 유형"속성에는 "사과", "배"및 "주황색"과 같은 가능한 클래스가 있습니다. 속성 "색상"에는 "녹색", "빨간색", "노란색"및 "주황색"과 같은 가능한 클래스가 있습니다. 각 샘플은 과일의 이미지이고 레이블은 두 속성 모두에 대해 출력되며 각 레이블은 해당 속성의 가능한 클래스 중 하나입니다.
다중 클래스 다중 출력 (다중 작업 분류라고도 함) 작업을 처리하는 모든 분류자는 특수한 경우로 다중 레이블 분류 작업을 지원합니다. 다중 작업 분류는 모델 공식이 다른 다중 출력 분류 작업과 유사합니다. 자세한 정보는 관련 추정기 문서를 참조하십시오.
'AI 머신러닝' 카테고리의 다른 글
| [AI머신러닝] hyperparameter optimization- Bayesian optimization (0) | 2021.05.07 |
|---|---|
| [Dacon] Bit trader season 2 ppt (0) | 2021.04.19 |
