시계열에 대한 몇가지 선형적인 통계 모델이 있는데 이 모델들은 선형 회귀와 관련이 있다. 하지만 비시계열 데이터에 적용되는 표준 방법과는 다른데, 각 데이터를 서로 독립적으로 가정하지 않고 같은 시계열 내 데이터 간 발생하는 상관관계를 알 수 있게 해준다.
자기회귀 autoregressive(AR) 모델
이동평균 moving average(MA) 모델
자기회귀누적이동편균autoregressive integrated moving average(ARIMA) 모델
벡터자기회귀 vector autoregression(VAR) 모델
계층형(hierachical) 모델
이러한 모델들은 전통적으로 시계열 예측의 핵심 요소이며 학계에서부터 산업에 이르기까지 다양한 상황에 모델링을 지속적으로 사용한다.
선형회귀를 사용하지 않는 이유
선형회귀 분석은 독립항등분포(IID : Independently and identically distributed) 데이터가 있다는 것을 가정한다. 따라서 시계열 데이터에는 해당되지 않는다. 시계열 데이터는 시간에 가까운 데이터일수록 서로 강한 관계를 맺는 경향이 있다. 즉, 시계역 데이터에 시간적인 상관관계가 없다면 이 데이터는 미래를 예측하거나 시간의 역동성을 이해하는 등 전통적인 시계열 작업에 유용하다고 보기 어렵다.
시계열에서 선형회귀가 유용하지 않다고 과하게 강조하는 경우가 있다. 이는 사실이 아니며 다음과 같은 조건이 충족될때 일반적인 최소제곱선형회귀 모델을 시계열 데이터에 적용해 볼 수 있다.
시계열 행동에 대한 가정
- 시계열은 예측 변수에 대한 선형적 반응을 보인다.
- 입력 변수는 시간에 따라 일정하지 않거나 다른 입력 변수와 완벽한 상관관계를 갖지 않는다. 이는 단순히 데이터의 시간 차원을 설명하기 위해 전통적인 선형회귀의 독립변수에 대한 요구 사항을 확장한 것이다.
오차에 대한 가정
- 각 시점의 데이터에 대해 모든 (앞뒤의) 시기의 설명변수 에 대한 예상 오차 값은 0이다.
- 특정 시기의 오차는 과거나 미래의 모든 시기에 대한 입력과 관련이 없습니다. 따라서 오차에 대한 자기상관 함수 그래프는 어떠한 패턴도 띄지 않는다.
- 오차의 분산은 시간으로부터 독립적이다.
이러한 가정이 성립된다면 보통최소죄곱회귀(ordinary least squares regression)은 주어진 입력에 대한 계수의 비편향추청량(unbiased estimator)이 되며 이는 시계열 데이터에서도 마찬가지다. 이때 추정치의 표본 분산은 표준선형회귀와 수학적으로 동일한 형태를 갖는다.. 따라서 앞서 나열된 가정을 충족하는 데이터가 있다면 선형회귀를 적용할 수 있다. 즉 시계열 동작에 대해 명확하면서도 간단한 직관을 얻는 데 도움이 된다. 앞에서 언급한 데이터의 요구 사항은 비시계열 데이터에 적용된 표준선형회귀의 요구 사항과 유사하다. 다만 데이터세스이 시간적 특성을 강조하는대한 몇가지 선형적인 통계 모델이 있는데 이 모델들은 선형 회귀와 관련이 있다. 하지만 비시계열 데이터에 적용되는 표준 방법과는 다른데, 각 데이터를 서로 독립적으로 가정하지 않고 같은 시계열 내 데이터 간 발생하는 상관관계를 알 수 있게 해준다.
CAUTION_ 선형회귀를 강요하지 않기.
데이터가 필수 가정을 충족하지 못할 때 선형회귀를 적용한다면 다음과 같은 결과 발생.
- 계수가 모델의 오차를 최소화하지 않는다.
- 충족되지 않은 가정에 의존하므로 계수가 0인지 아닌지를 결정하기 위한 p-value값이 무족확함. 이는 계수의 유의성 평가가 잘못되었음을 의미
적절히 사용될 수 있는 상황에서 선형회귀는 단순성과 투명성을 제공할 수 있지만, 모델 자체가 부정확하다면 이러한 내용조차 제공하지 못하는 것이 당연.
표준선형회귀에 요구되는 가정을 지나칠 정도로 엄격하게 적용해 선형회귀 기법을 사용할 수 없게 된 것은 아닌지 의문을 가져보는 것이 타당하나 실제로 현업의 분석가는 모델의 가정을 통해 자유를 얻는다. 이러한 태도의 잠재적인 단점을 잘 이해하고 있는 경우만 생산적일 수 있다.
모델의 가정을 고수하는 것의 중요성은 영역과 분야에 따라 크게 달라진다. 때로는 보상대비 결과가 심각하지 않아서 기본적인 가정을 충족하지 않는다는 것을 알아도, 이를 모델에 적용하는 경우가 있다. 가령 높은 빈도로 발생하는 거래라면 데이터가 모든 표준적인 가정을 엄격히 따르지 않더라도 선형 모델을 사용하는 것이 꽤 인기가 있다.
NOTE_비편향추정량이란 무엇일까?
추정치가 과대/과소 평가된 것이 아니라면, 해당 추정치는 비편향추정량을 사용한다고 볼 수 있다. 비편향추정량은 좋은 경향을 지닌다. 다만 통계적, 기계학습적 문제 모두에 적용되는 편향과 분산 사이의 트레이드 오프를 잘 알고 있어야만 한다. 이 트레이드 오프는 파라미터 추정에 대해 편향이 낮은 모델일수록 파라미터 추정에 대한 높은 분산을 지니는 경향이 있습니다. 파라미터 추정에 대한 분산은 데이터 내의 서로 다른 표본에 걸쳐 추정치가 얼마나 가변적인지를 반영한다.
시계열을 위해 개발된 통계 모델
시계열의 미래 값의 과거 값의 함수라고 정의하는 매우 간단한 자기회귀 모델을 시작으로, 단변량 시계열 데이터를 위해 개발된 다양한 방법들을 살표볼 것이다. 그런 다음, 다변량 시계열에 대한 벡터자기회귀분석을 포함해서 GARCH 모델과 계층적 모델링과 같은 특수한 시계열 방법들을 추가로 알아보고 점점 더 복잡한 모델을 다룰 것이다.
자기회귀 모델(autoregressive(AR))모델
자기회귀모델은 과거가 미래를 예측한다는 직관적인 사실에 의존한다. 따라서 특정 시점 t의 값은 이전 시점들을 구성하는 값들의 함수라는 시계열 과정을 상정한다.
대수학을 활용한 AR처리 과정의 제약 사항 이해
시계열 이외의 정보가 없을 경우 첫번째로 시도하는 방법이 자가회귀다. 자가회귀는 과거 값들에 대한 회귀로 미래 값을 예측하는 방법이다. 가장 간단한 AR모델인 AR(1) 모델이 설명하는 시스템은 다음과 같다.
y_t = b_0 + b_1 * y_t-1 + e_t
시간 t에서 계열의 값은 상수 b_0, 이전 시간 단계에서 값에 상수를 곱한 b_1*y_t-1 그리고 시간에 따라 달라지는 오차항 e_t에 대한 함수다. 여기서 오차항은 일정한 분산 및 평균 0을 가진다고 가정. 여기서 자가회귀라는 용어는 직전 시간만을 되돌아보는 AR(1)모델을 의미. 또한 AR(1)모델은 하나의 원인 변수만 지난 간단한 선형회귀 모델과 동일한 형식을 가짐 즉 다음과 같이 매핑됨.

b_0와 b_1값을 알고 있다면 주어진 y_t-1 조건에서의 y_t 기댓괎과 분산 모두를 계산할 수 있음.
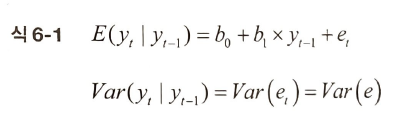
이 표기법을 일반화하면 현재 값이 의존하는 가장 최근 값들을 p로 조절할 수 있게 해주므로 AR(p)라는 과정을 생성할 수 있다.
이번에는 전통적인 표기법을 살펴보겠다. 여기서 사용된 파이는 자가회귀계수(autoregression coeffcient를 나타낸다.

3장에서 논의된 바와 같이, 시계열 분석의 핵심 개념은 정상성. 정상성은 AR모델을 포함한 많은 시계열 모델에서 기본으로 가정한다.
AR 모델이 정상인지에 대한 조건은 정상성의 정의로부터 결정된다. 계속해서 가장 간단한 AR 모델인 식 6-2의 AR(1)에 집중해 보자.

과정이 정상이라고 가정하고,